
1. 部分数据结构和内部编码
1. 如下图所示
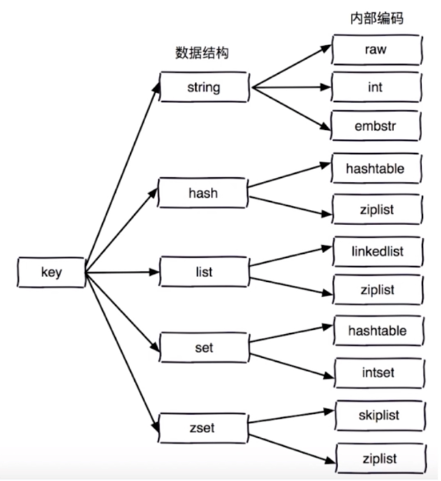
2. 每个数据类型都会有两种内部实现,一种是以空间换时间,另一种是时间换空间,用来处理不同的需求。
2. Redis的单线程执行模型
1. Redis对于命令的执行是串行的,也就是单线程的,在同一时刻只会执行一条命令。
2. Redis以单线程执行命令,但其速度很快,原因在于:
- 操作的数据全部存储在内存中,而内存中的数据读写操作是非常快的。(主要原因)
- 采用非阻塞IO
- 单线程执行避免了线程间的切换和竞态消耗
3. 单线程执行需要注意的一些问题:
- Redis在同一时刻只能执行一条命令,其他命令将会进行排列等待
- 不要执行执行速度很慢的命令,比如keys/flushall/flushdb等命令
3. 字符串(string)类型数据
1. key-value结构:key是一个普通字符串,string类型的value值可以是一个字符串、数字(对于数字会在内部做一个自动的转换,将字符串转为数字)或者二进制码,最大长度为512Mb
2. 使用场景:最常用的就是用作缓存,或者用做计数器、分布式锁等。
3. 使用命令:
- set key value:插入key-value数据,时间复杂度为O(1),key若是已存在,那么就进行value更新
- setnx key value:key不存在才会插入数据,时间复杂度为O(1),即该命令只用来插入数据
- set key value xx:key存在才会更新数据,时间复杂度为O(1),即该命令只用来更新数据
- mset key value [key value ...]:批量插入key-value数据,时间复杂度为O(n)
- get key:依据key来获取value数据,时间复杂度为O(1)
- mget key [key ...]:批量依据key来获取value数据,时间复杂度为O(n)
- del key:依据key来删除数据,时间复杂度为O(1)
- incr key:如果key对应的value是一个数字,那么可以将该value值加1,如果不存在key,则自增后执行get key得到1
- decr key:如果key对应的value是一个数字,那么可以将该value值减1,如果不存在key,则自减后执行get key得到-1
- incrby key num:如果key对应的value是一个数字,那么可以将该value值加num,如果不存在key,则自增后执行get key得到num
- decrby key num:如果key对应的value是一个数字,那么可以将该value值减num,如果不存在key,则自减后执行get key得到-num
- getset key newValue:插入新的value字符串并且返回旧的value字符串,时间复杂度为O(1)
- append key newValue:向key对应的旧value后追加newValue,时间复杂度为O(1)
- strlen key:获取key对应的value字符串的长度,时间复杂度为O(1),注意一个中文对应两个字节长
- incrbyfloat key floatnum:浮点数运算,如果key对应的value是一个数字,那么可以将该value值加floatnum,如果不存在key,则自增后执行get key得到floatnum,没有浮点数自减运算,但是可以通过加上一个负数来实现浮点数自减,时间复杂度为O(1)
- setrange key index value:将key对应的字符串中index下标处字符设置为value,下标从0开始
- getrange key start end:获取key对应的字符串中从下标start到end之间的字符串
4. 应用:
- 以个人博客访问计数为例,统计每一个博客页面的访问次数:incr userId:page ,userId代表的就是用户id,而page就代表每一个博客页面,userId:page组合起来就是一个key,通过自增来统计每个用户的每篇博客的访问量
4. 哈希(hash)类型数据
1. key-value结构:key是一个普通字符串,而value部分则分成两个部分,一个是属性名(field),另一个就是属性值(fvalue),可以通过可以来给value部分添加一个属性,实际上hash类型数据类似于关系型数据库,关系型数据库的表中的一行数据对应的就是一个hash类型key所对应的数据;在每一条hash类型数据的value部分中,field不能有重复的,而fvalue可以
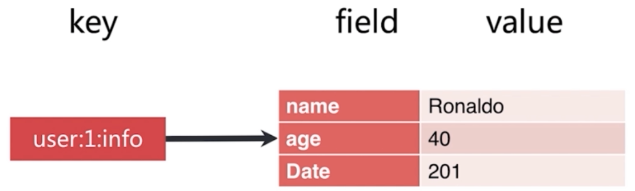
2. 使用命令:hash相关命令均以 h 开头
- hset key field value:添加key对应的field以及field对应的value数据
- hmset key field value [key field value ...]:批量插入key field value数据,时间复杂度为O(n)
- hsetnx key field value:key对应的field不存在才会插入数据,时间复杂度为O(1),即该命令只用来插入数据不更新数据
- hget key field:获取key对应的field的value数据
- hmget key field [field ...]:获取key对应的一批field的value数据,时间复杂度为O(n)
- hgetall key:获取key对应的所有的field以及value数据,时间复杂度为O(n)
- hvals key:获取key对应的所有的field的value数据,时间复杂度为O(n)
- hkeys key:获取key对应的所有的field,时间复杂度为O(n)
- hdel key field:删除key对应的field以及value数据
- hexists key field:判断是否存在key对应的该field
- hlen key:获取key对应的field数量
- hincrby key field intCounter:如果key对应的field对应的value是一个数字,那么可以将该value值加intCounter,如果不存在field,则自增后执行hget key field得到intCounter,自减通过增加负数即可实现
- hincrbyfloat key field floatCounter:浮点数自增,自减通过增加负数即可实现
5. 列表(list)类型数据
1. key-value结构:key是一个普通字符串,而value部分则是一个双向队列结构的数据,value部分的集合中的元素是有序的(按插入顺序排列)、可重复的,注意,列表最左端的代表头元素,而最右端的表示末尾元素,末尾元素下标可以是列表元素数量len-1,也可以用-1来表示,而开头元素下标只能是0
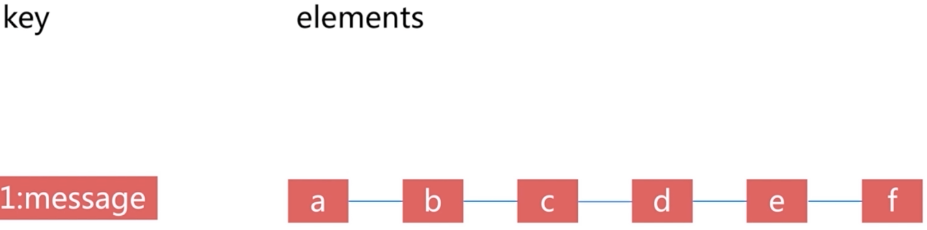
2. 使用命令:
- rpush key value [value ...]:从队列右边添加多个value,时间复杂度为O(n)
- lpush key value [value ...]:从队列左边添加多个value,时间复杂度为O(n)
- linsert key after|before value newValue:在某个指定数据之前或之后插入一个新数据,时间复杂度为O(n)
- lpop key :从队列左边移出第一个数据并返回
- blpop key timeout:lpop key 的阻塞版本,timeout为阻塞超时时间,timeout=0表示永不阻塞
- rpop key :从队列右边移出第一个数据并返回
- brpop key timeout:rpop key 的阻塞版本,timeout为阻塞超时时间,timeout=0表示永不阻塞
- lrem key count value:时间复杂度为O(n)
- count>0,从左到右,从列表中删除最多count个与value相等的值
- count<0,从右到左,从列表中删除最多 -count个与value相等的值
- count=0,从列表中删除所有与value相等的值
- ltrim key start end:截取保留下标从start到end范围之间的数据集合,时间复杂度为O(n) ,下标从0开始
- lrange key start end:获取(不删除)列表指定下标从start到end范围之间的所有数据,时间复杂度为O(n) ,下标从0开始
- lindex key index:获取(不删除)列表指定下标的数据,下标从0开始,时间复杂度为O(n)
- llen key:获取列表的长度,时间复杂度为O(1)
- lset key index newValue:设置列表中某个下标的新值
6. 集合(set)类型数据
1. key-value结构:key是一个普通字符串,而value部分则是一个数据集合,集合中的元素是无序的、不可重复的,而且支持两个集合之间的并(求并集)、交(求交集)、差(求差集)操作。
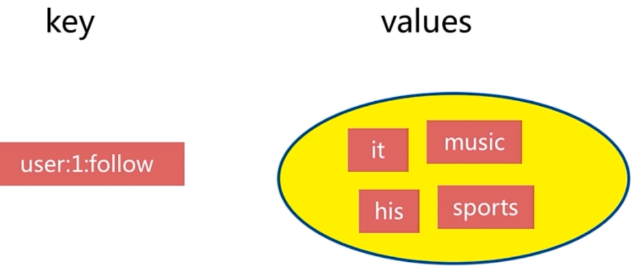
2. 使用命令:
- sadd key element [element ...]:向key所代表的集合中添加多个element,如果某个element已经存在则该element无法添加,时间复杂度为O(n)
- srem key element:从集合中移除element,时间复杂度为O(1)
- scard key:返回集合中的元素数量
- sismember key element:判断element是否存在集合中,如果存在则返回1,否则返回0
- srandmember key count:从集合中随机抽取count个元素(不删除元素)
- spop key :从集合中随机移除一个元素并返回该元素(删除元素)
- smembers key:获取集合中的所有元素
- sdiff key1 key2:获取key1与key2两个集合之间的差集,也就是key1中有的元素而key2中没有的元素
- sinter key1 key2:获取key1与key2两个集合之间的交集,也就是key1、key2中都有的元素
- sunion key1 key2:获取key1与key2两个集合之间的并集,也就是key1、key2中的所有元素
3. 应用场景:微博的用户抽奖,就可以利用srandmember key count从参与转发的用户中随机抽取count个用户,共同关注的好友就可以利用集合间的交集操作来获取
7. 有序集合(zset)数据类型
1. key-value结构:key是一个普通字符串,而value部分则是由两部分组成,一个是score另一个就是value数据;zset集合中的元素是有序的(通过score来实现)、不可重复的(score可重复, element不可重复),而且支持两个集合之间的并(求并集)、交(求交集)、差(求差集)操作。

2. 使用命令:
- zadd key score element [score element ...]:向key所代表的集合中添加多个score element,如果某个element已经存在则该element无法添加,时间复杂度为O(logN)
- zrem key element [element ...]:从集合中移除element,时间复杂度为O(n)
- zscore key element:返回集合中该element的score值
- zincrby key incrScore element:增加或减少元素的score值
- zcard key:返回集合中的元素数量
- zrange key start end [withscores]:返回指定索引start到end范围内的升序元素,索引值从0开始,时间复杂度为O(log(n)+m)
- zrangebyscore key minScore maxScore [withscores]:返回score值在minScore 到maxScore 之间的元素,时间复杂度为O(log(n)+m)
- zcount key minScore maxScore:返回score值在minScore 到maxScore 之间的元素个数,时间复杂度为O(log(n)+m)
- zremrangebyrank key start end:删除按升序排序中从start到end之间的元素,排序从0开始,时间复杂度为O(log(n)+m)
- zremrangebyscore key minScore maxScore:删除按升序排序中score值在minScore 到maxScore 之间的元素,时间复杂度为O(log(n)+m)
- zinterstroe key1 key2:获取key1与key2两个集合之间的交集,也就是key1、key2中都有的元素
- zunionstroe key1 key2:获取key1与key2两个集合之间的并集,也就是key1、key2中的所有元素
3. 应用场景:网站中的数据排行榜可以用zset实现